



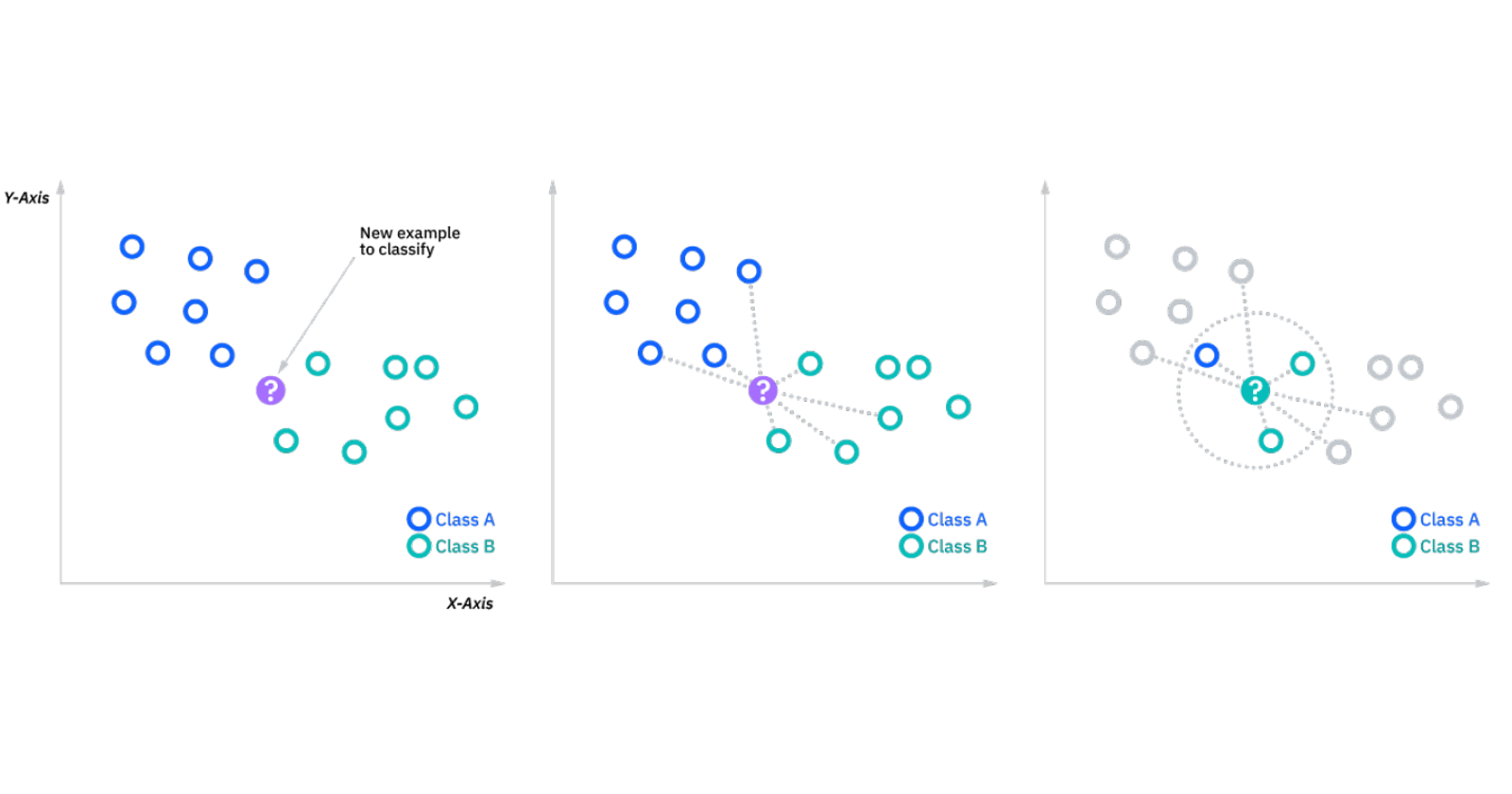
K-Nearest Neighbors (KNN), a non-parametric lazy learning technique, is considered one of the best techniques for classification. Unlike other classification algorithms like Logistic Regression, Naïve Bayes, etc, the biggest advantage of KNN is that it does not make any assumptions about the data. This makes KNN suitable for any practical data which generally doesn’t tend to follow any theoretical assumptions. However, on the downside, KNN has heavy computational demands and thus it can be difficult for a single machine to implement KNN on a large dataset. One of the ways to tackle this computational demand is by implementing KNN using distributed computation such as the MapReduce programming model. The MapReduce programming model is a parallel processing technique used to process large volumes of data by breaking it down into smaller chunks and processing them in parallel across a distributed computing infrastructure. Therefore, in this article, instead of using the ‘sklearn’ library to implement KNN, KNN will be implemented using the MapReduce programming model for classification.
In this article, first, we will see how we can use the MapReduce programming paradigm to implement KNN and then use a Python library called ‘mrjob’ to implement the same. Once done, the implementation will be tested locally on a publicly available dataset.
Prerequisites
Before going ahead, I am assuming that you have a fundamental understanding of the MapReduce programming paradigm and KNN algorithm. If not, I will highly recommend understanding these two concepts first and then again coming back to this article.
MRJOB Python Library
‘mrjob’ is a Python library that provides a simple and easy-to-use interface for writing MapReduce jobs that can be run on various Hadoop clusters or other distributed computing infrastructures such as Amazon EMR or Google Cloud Dataproc. The library abstracts away many of the low-level details of MapReduce programming, allowing us to focus on writing high-level code that defines the map and reduce phase of the job. You can always explore and learn more about ‘mrjob’ by reading its documentation. Click here for its documentation. Now let’s start implementing KNN using the ‘mrjob’ library.
Since, we are writing the whole code from scratch, to make our implementation more efficient, instead of calculating predictions for a single value of K neighbors, we will calculate predictions for multiple values of K neighbors in a single go.
Input Arguments
train_path(String): Path to the training dataset
test_path(String): Path to testing dataset.
max_k(Integer): Maximum K number neighbors to consider for predictions. For example, if max_k = 5 then this implementation will predict each K from 1 to 5.
Output
A JSON file of predicted labels for each test point and each K from 1 to max_k.
Working of MapReduce Job
In this implementation, our MapReduce Job will give us the labels of the nearest max_k neighbors for each test data point. Using these labels, we will make predictions for each K from 1 to max_k using a runner script.
There are three phases in our MapReduce job: Mapper, Combiner, and Reducer. A combiner is also introduced along with a mapper and reducer to make the implementation more efficient.
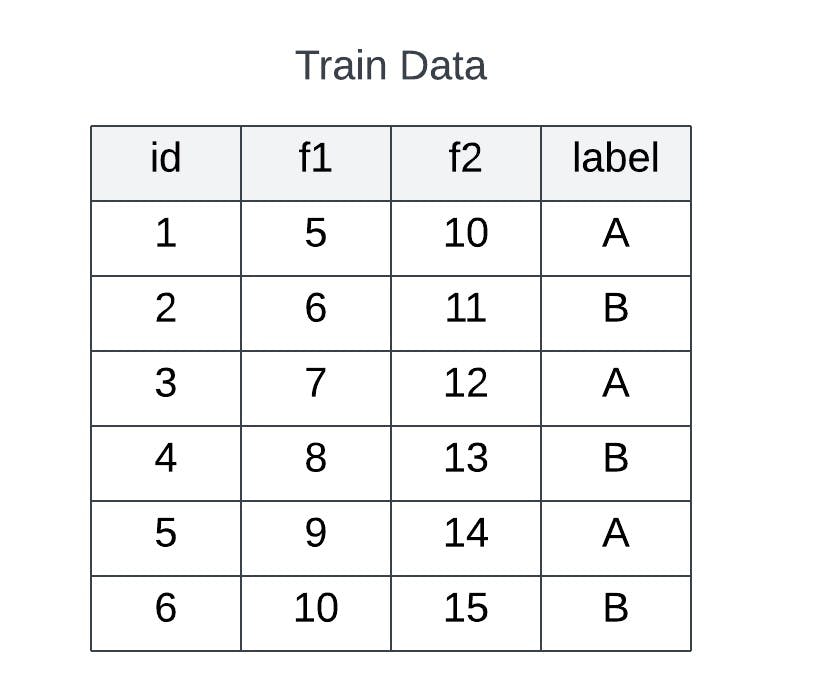
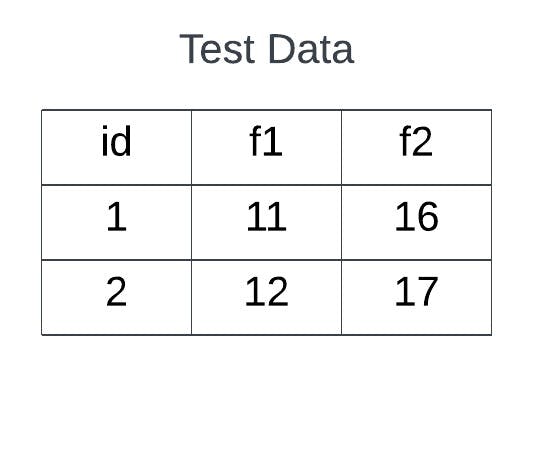
Let’s understand the working of this whole implementation using dummy data. Assume that we have train and test datasets with two features f1 and f2 as shown in the below figures
Mapper Phase
Initially, the train data will be broken down into smaller chunks and each smaller chunk will be then processed in parallel by a mapper. Each mapper will calculate the euclidean distance between every test data point and train point data. After calculating the distance, it will emit the id of the test datapoint as the intermediate key and a tuple of calculated distance and the label of the corresponding train data point as the intermediate value. After that, Hadoop will sort the intermediate key-value pairs by their keys and group together all pairs with the same key.

The pseudo-code for the mapper phase is shown below.

Combiner Phase
In the combiner phase, the output of each mapper is optimized locally. The input of the combiner is the intermediate key and a list of values. In our case, it is the id of the test datapoint and list of euclidean distance and label. The combiner will reduce the output of the mapper by emitting only max_k(In this case max_k = 2) key-value pairs with the smallest distance. The Hadoop framework will again group all the values by key and pass them to the reducer.
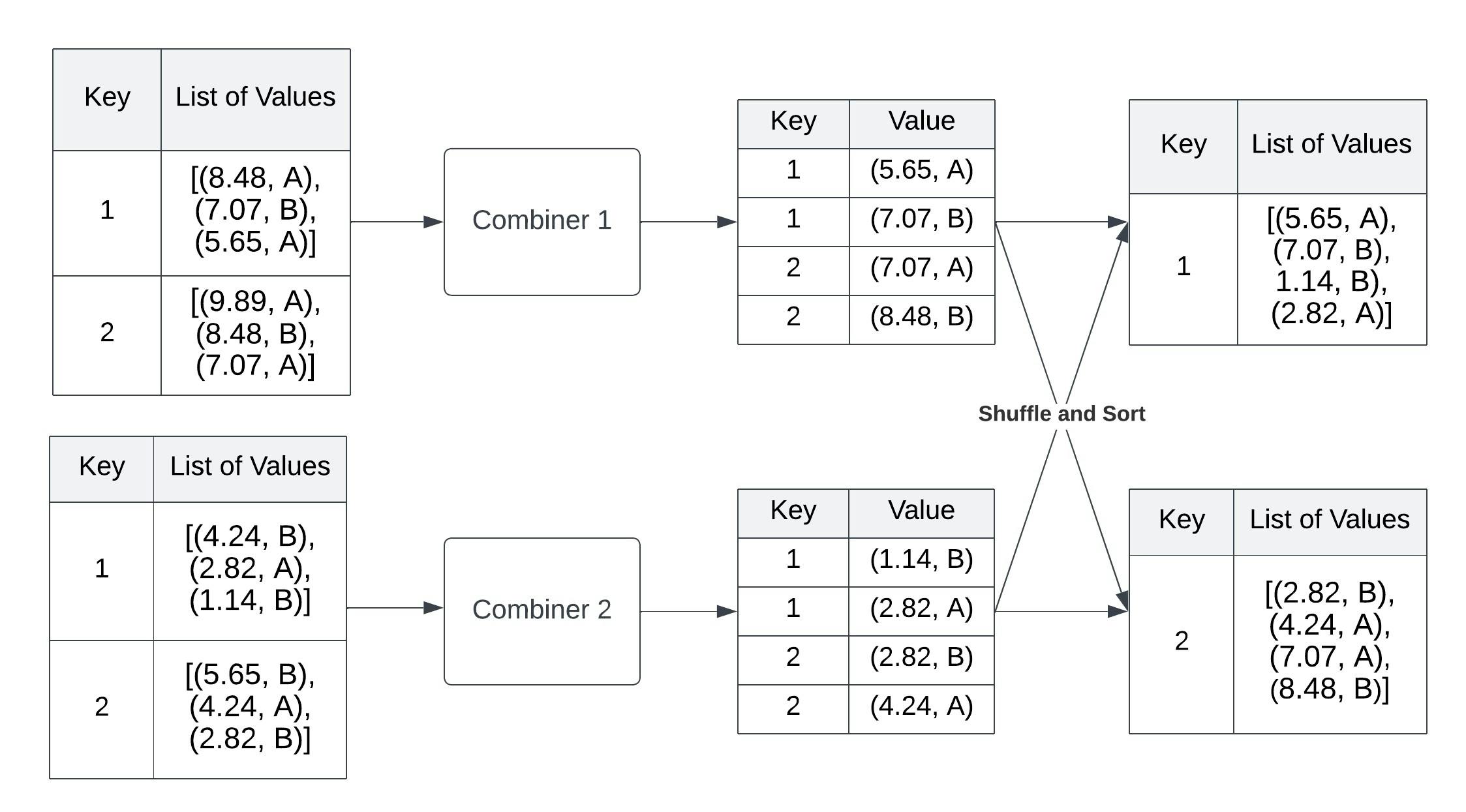
The pseudo-code for the combiner is shown below

Reducer Phase
The reducer now will reduce the output from all the combiners. Exactly like the combiner, the reducer will only emit only max_k (In this case max_k =2) key-value pairs with the smallest distance.

The pseudo-code of the reducer is shown below.

Implementation of MapReduce Job Using MRJOB
The code for the Mapper. Combiner and Reducer are shown below.
from mrjob.job import MRJob
import csv
class KNNMRJob(MRJob):
DELIMITER = ","
minmaxdata = []
def configure_args(self):
super(KNNMRJob, self).configure_args()
self.add_passthru_arg("--max_K", type=int, help="Max value of K")
self.add_file_arg("--test", help='Path of test dataset')
def mapper(self, _, row):
train_values = row.strip().split(self.DELIMITER)
train_nparray = np.array(train_values[1:-1], dtype=float)
with open(self.options.test, 'r') as test_file:
test_csv_reader = csv.reader(test_file)
for test_values in test_csv_reader:
line_values = np.array(test_values[1:-1], dtype=float)
#calculate elucidian distance
sum_vectors = np.sum(np.square(line_values - train_nparray))
dist = np.sqrt(sum_vectors)
yield test_values[0], (dist, train_values[-1])
def combiner(self, key, values):
pq = []
values = list(values)
for value in values:
if len(pq) < self.options.max_K:
pq.append(value)
else:
max_value = max(pq, key=lambda x: x[0])
if max_value[0] < value[0]:
pq.remove(max_value)
pq.append(value)
for value in pq:
yield key, value
def reducer(self, key, values):
pq = []
for value in values:
if len(pq) < self.options.max_K:
pq.append(value)
else:
max_value = max(pq, key=lambda x: x[0])
if max_value[0] > value[0]:
pq.remove(max_value)
pq.append(value)
for value in pq:
yield key, value
if __name__ == '__main__':
KNNMRJob.run()
Now to run the MapReduce job, process its output and predict the labels for each test point, we will write a runner script. The code for the runner script is shown below.
import sys
from KNNMRJOB import KNNMRJob
import json
import pandas as pd
if __name__ == '__main__':
args = sys.argv[1:]
print(args)
dict_ = {}
knnmrjob = KNNMRJob(args)
with knnmrjob.make_runner() as runner:
print('Runner Started')
runner.run()
print('Runner End')
for key, value in knnmrjob.parse_output(runner.cat_output()):
dict_.setdefault(key, []).append(value)
print('For Loop End')
predicted_labels = {}
for key, value in dict_.items():
lst_sorted = sorted(value, key=lambda x: x[0])
# print(lst_sorted)
lst_labels = [x[1].strip() for x in lst_sorted]
for i in range(1, len(lst_labels)+1):
max_ = max(set(lst_labels[:i]), key = lst_labels[:i].count)
predicted_labels.setdefault(key, []).append(max_)
with open("predictions.json", "w") as json_file:
json.dump(predicted_labels, json_file) # encode dict into JSON
This runner script will programmatically run the MapReduce job and use majority voting to predict the labels for each test datapoint and each K from 1 to max_k.
Test the Implementation Locally
To test the implementation locally, we will use the Airline Passenger Satisfaction dataset publicly available on Kaggle. The know more about the dataset click here.
Now before we test our implementation on this dataset, we must pre-process the dataset and make it ready for our implementation of the KNN algorithm. All the heavy lifting has already been done and the details of the pre-processing are there in this jupyter notebook.
Once the data is pre-processed, save it as a CSV file and run the following command in the terminal to test our implementation of KNN on it. It has four command-line arguments
-r inline: To simulate Hadoop locally
--max_K 10: Set the max_K value.
--test ./test.csv: Path to the test dataset
./train.csv: Path to the train dataset
python runner.py -r inline --max_K 10 --test ./test.csv ./train.csv
The runner will run the MapReduce Job on the pre-processed dataset and give us the predictions for each test data point. The predictions are saved in the working directory as a JSON file. Using these predictions, we can calculate all different types of metrics to evaluate the performance of the algorithm on the pre-processed dataset. To keep things a little simple, only accuracy is calculated for each K. Again, refer to this jupyter notebook, it has all the details on how to calculate accuracy.
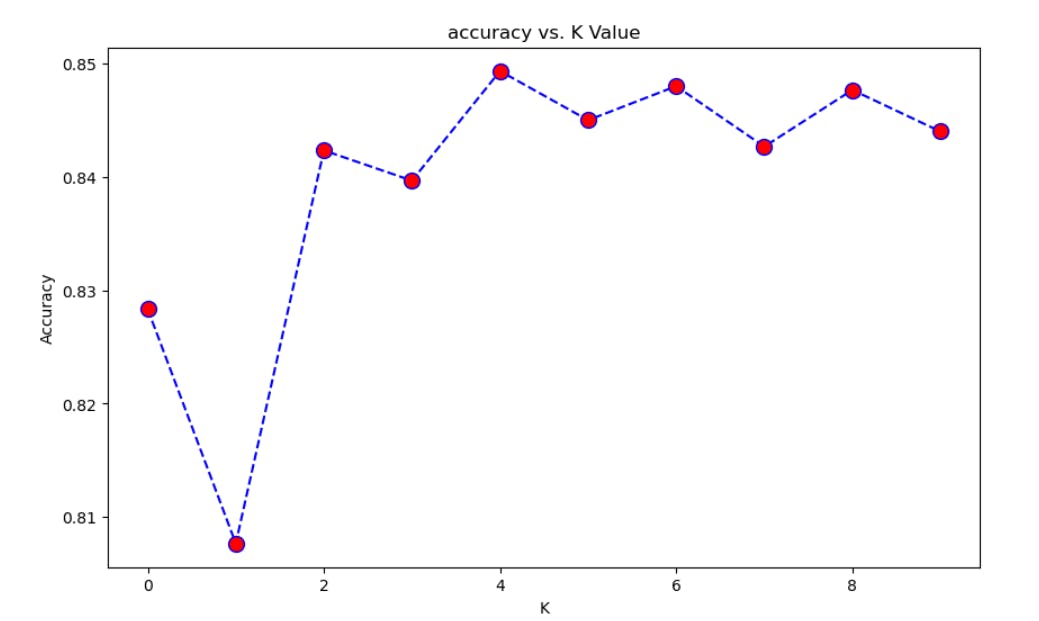
Conclusion and Future Work
In this article, we implemented KNN using the MapReduce programming paradigm and tested it locally on a publicly available dataset. In future, we will use the same implementation and use the Google Cloud Platform to test. So stay tuned!
If you like this blog and got to learn something new from it! Do comment down below and let me know. Also, if you are facing any errors, let me know in the comment section and I will try to resolve them. Do come to hang out with me on LinkedIn as well (LinkedIn Profile).